Runner Face Clustering with YOLO, InsightFace, HDBSCAN & OCR
The project detects runners in photos with a YOLO model
(yolo11n.pt), extracts face embeddings using the
InsightFace buffalo_l model, and clusters the
embeddings via HDBSCAN. Optional bib recognition relies on
EasyOCR.
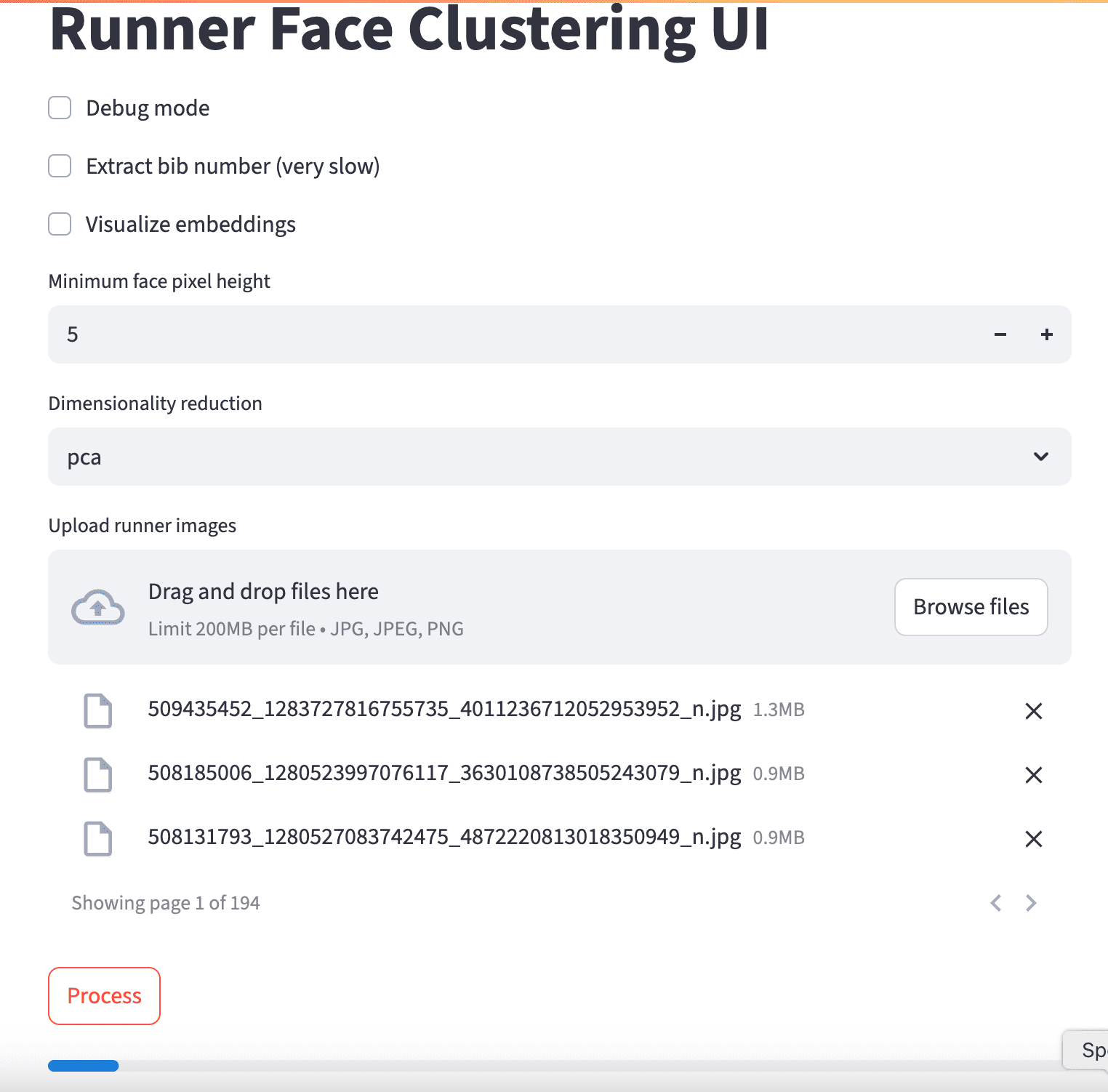
All processing is orchestrated in main.py and
exposed through app.py, a Streamlit UI. The web
interface lets you upload images, enable debug mode, toggle OCR,
and choose a dimensionality reducer (PCA or t‑SNE). A progress
bar tracks processing status. After clustering, results appear
in expandable sections and can be downloaded as a ZIP archive.
Each cluster directory inside output/
contains original images, body crops, and debug versions
annotated with face boxes and detected bib numbers. When
enabled, a 2‑D visualization of the embeddings
(output/embeddings.png) is also generated.
The Streamlit app is deployed at: runner-face-clustering.streamlit.app
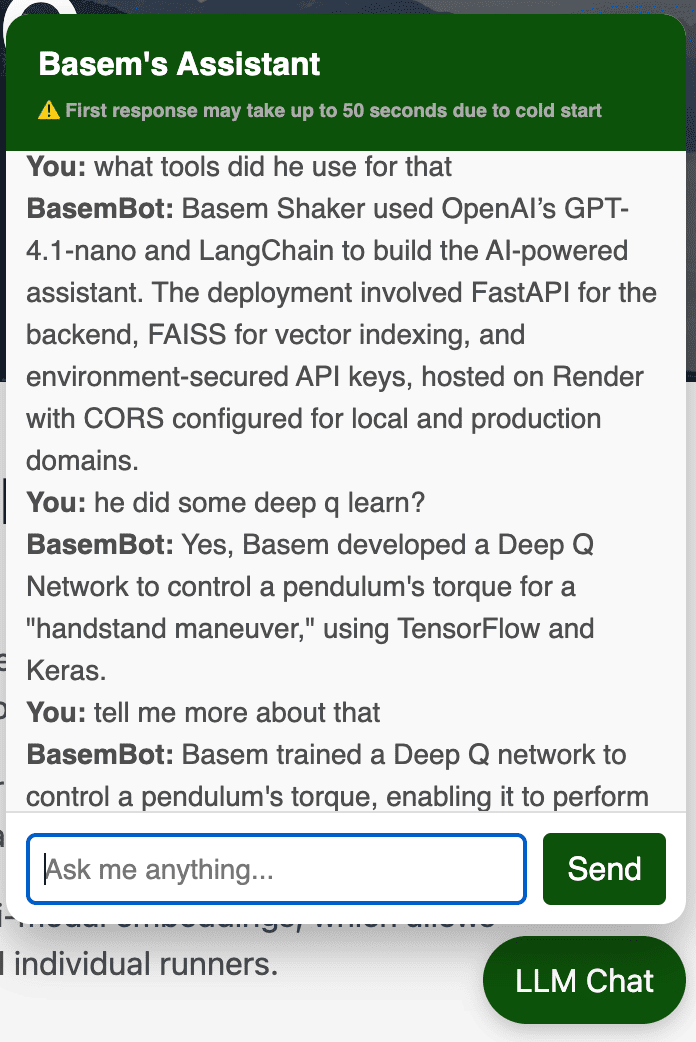
LLM-Powered Portfolio Chatbot with LangChain & OpenAI GPT-4.1
I built and deployed an AI-powered assistant on my portfolio site using OpenAI’s gpt-4.1-nano and LangChain. This chatbot allows visitors to ask natural language questions about my background, experience, and technical projects in real time.
The system architecture uses LangChain’s `RetrievalQA` over a FAISS vector store populated with data scraped and indexed from multiple pages of my site. This enables context-aware, precise answers grounded in actual portfolio content, rather than relying on static prompts.
To ensure efficiency, I cache the embeddings and index using FAISS to avoid repeated web scraping, and I tuned the LLM with a focused system prompt and a low temperature to keep answers accurate and concise. Chat memory is persisted client-side via `localStorage`, allowing continuity across page visits.
On the frontend, I implemented a lightweight popup widget using vanilla JavaScript and styled it for responsiveness. Features include a real-time "Generating answer..." indicator, keyboard input via the Enter key, and a startup note to explain the potential delay on first interaction due to cold start latency.
The full-stack app was deployed to Render using FastAPI and environment-secured API keys, with CORS configured for local and production domains. This demonstrates my ability to build and deploy intelligent assistants with optimized user experience, cloud hosting, and scalable LLM pipelines.
You can try it now by clicking the “LLM Chat” button on the bottom right of this page.
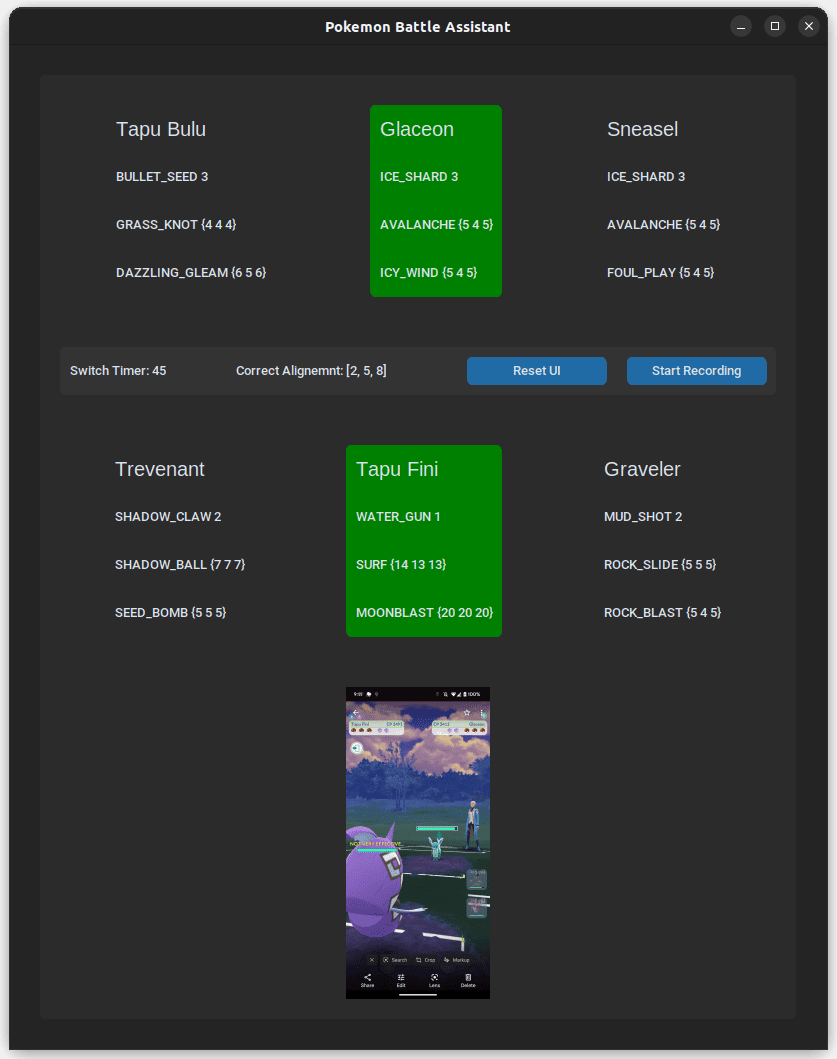
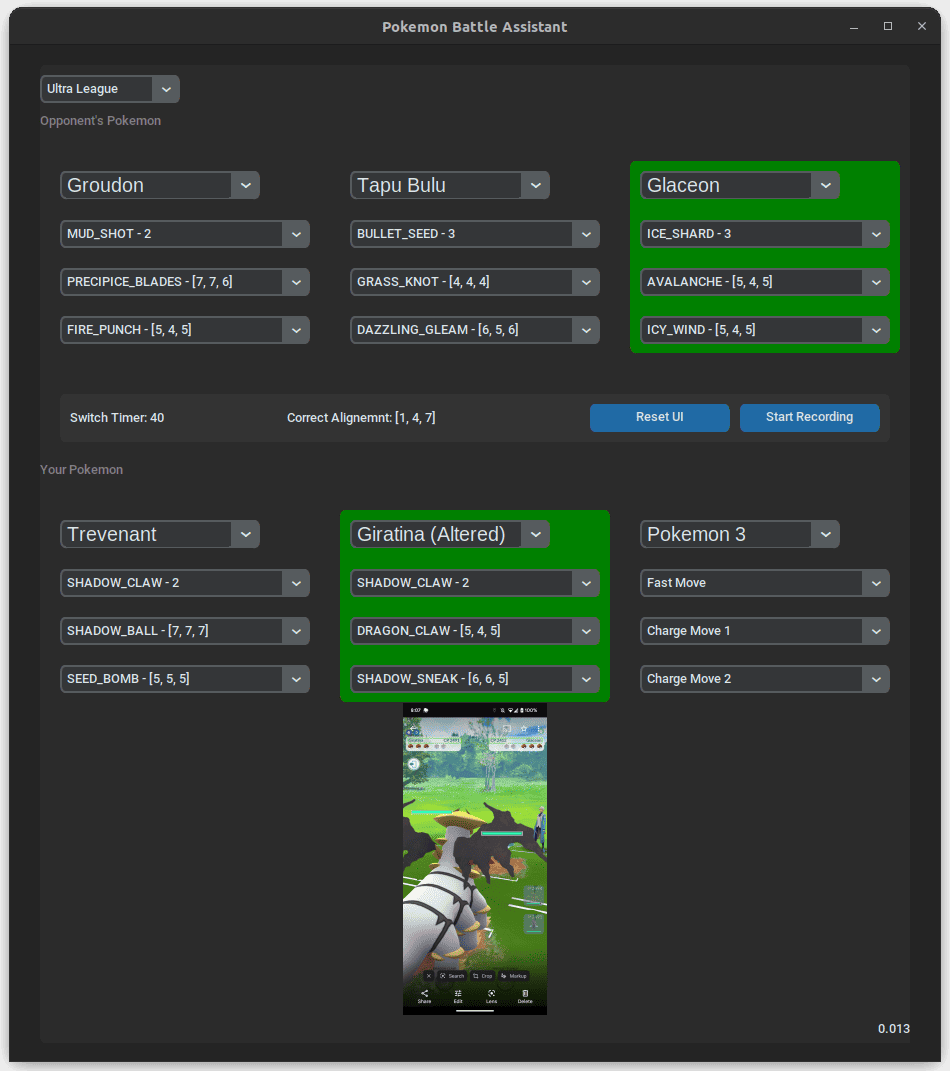
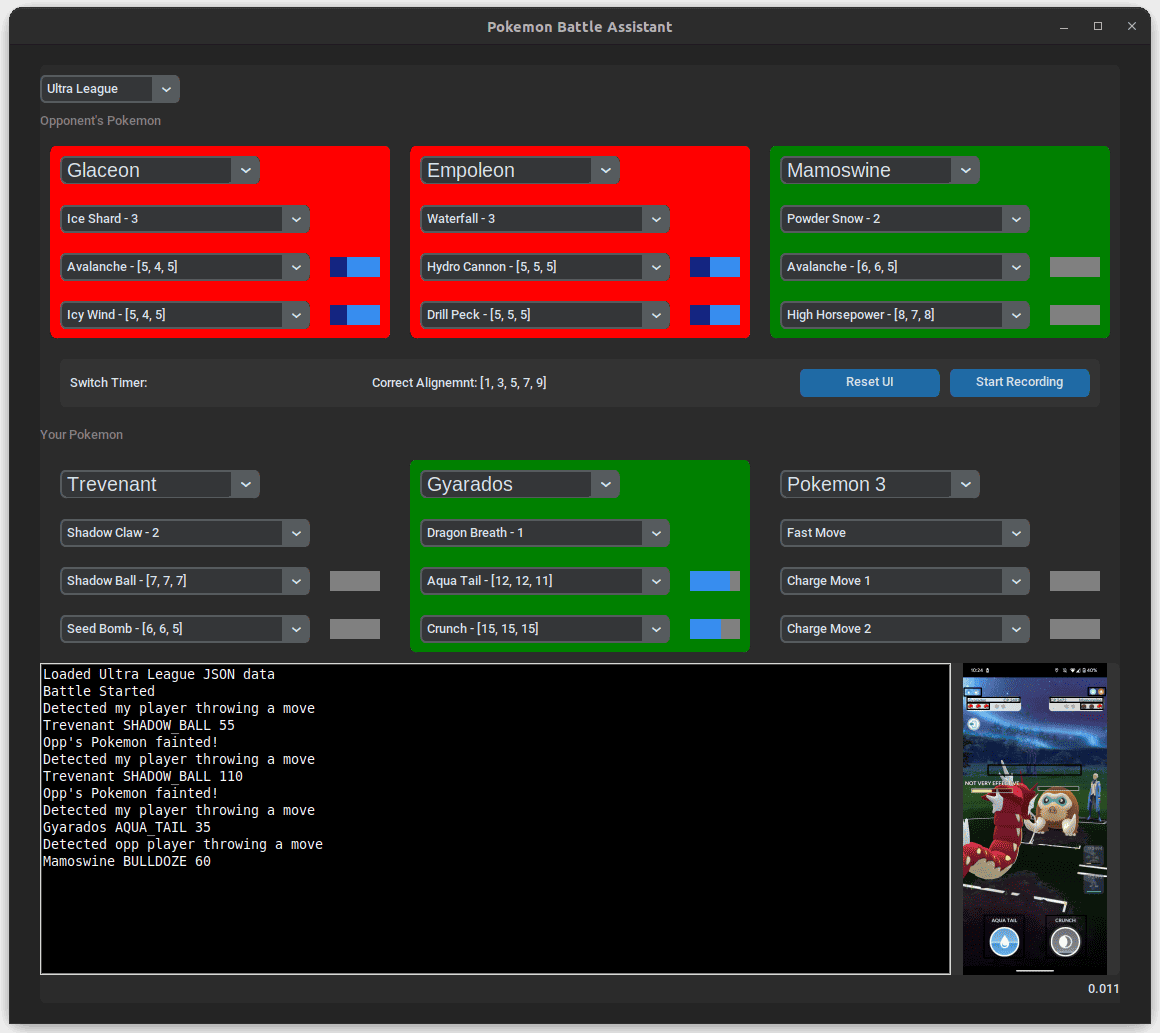
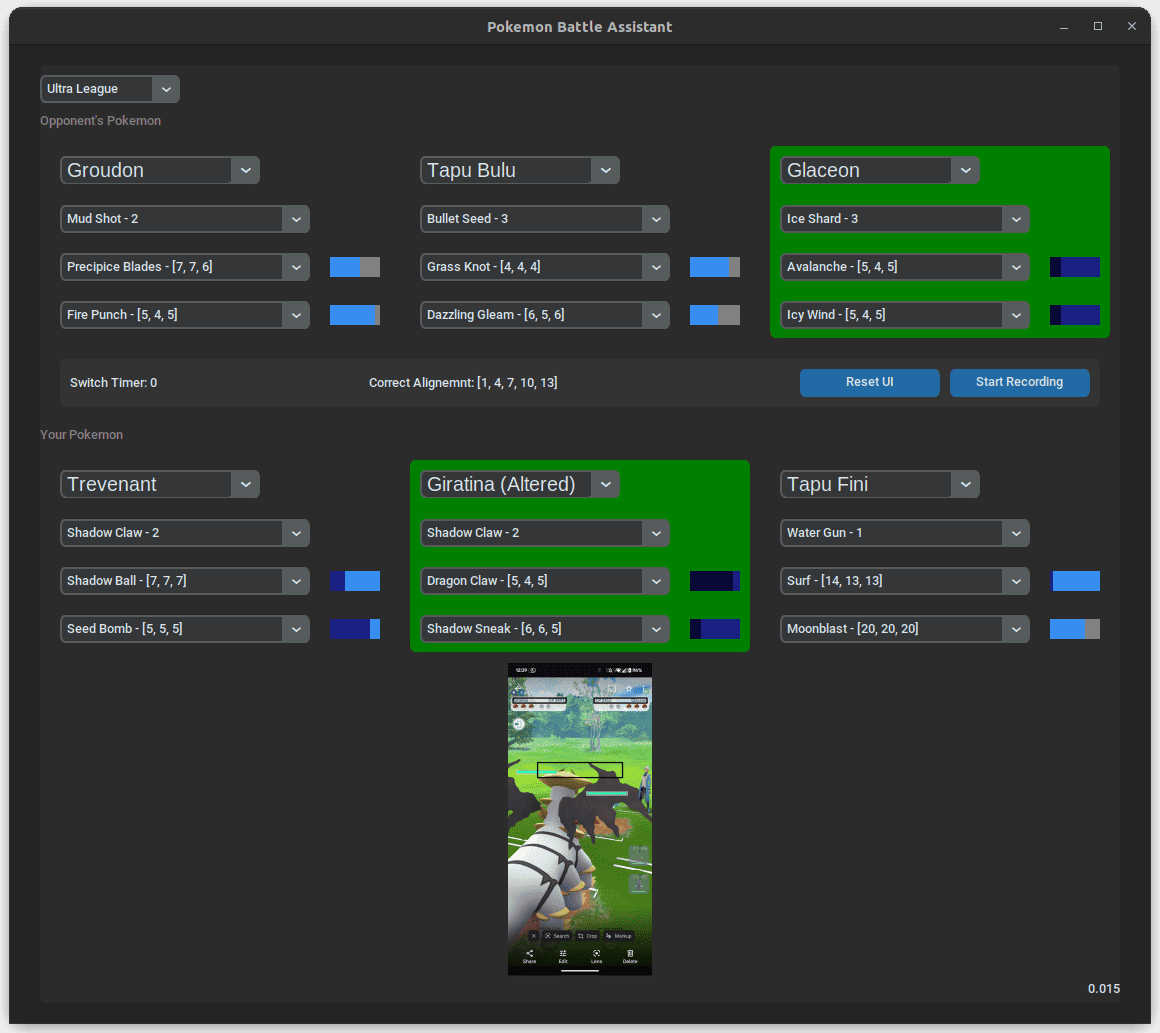
Pokémon GO PVP Battle Assistant
A Python tool that helps trainers manage Pokémon GO PVP battles.
The assistant reads your device screen via
scrcpy and overlays recommended moves, switch
timers, and energy counts in a Tkinter-based UI.
main.py orchestrates the process: it auto-detects
the battle league, keeps track of both players' Pokémon, and
logs results to battle_records.csv. The UI
highlights current Pokémon, records optional video, and updates
move data from PvPoke when needed.
Under the hood the project makes extensive use of Python libraries:
-
scrcpyandadbutilsto mirror the Android screen. -
OpenCVandNumpyfor real-time frame processing. -
Tesserocrfor OCR of move text and energy counts. -
Pandasfor tracking battles and updating datasets. -
CustomTkinterandTkinterfor the desktop interface. -
Ultralytics YOLOv8models for ongoing computer vision experiments.
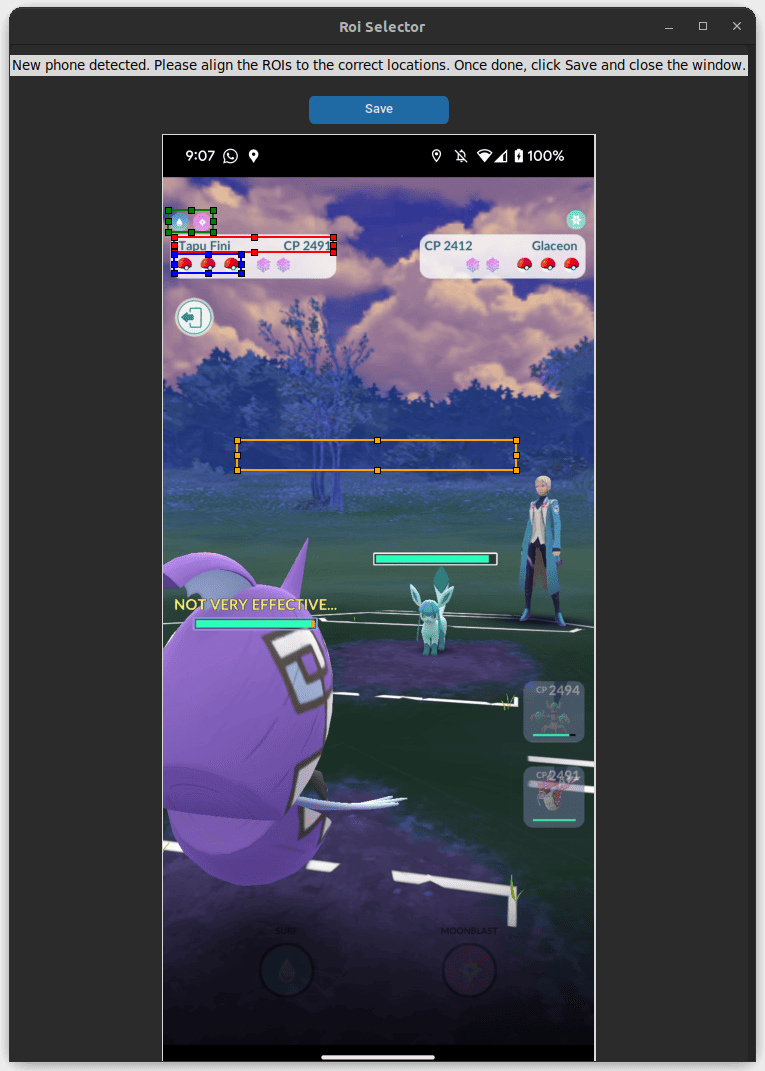
To use the assistant, connect an Android device with USB
debugging enabled and run
python main.py. Align the regions of interest when
prompted, then monitor battle progress with real-time move
recommendations.
Watch a demo of the assistant in action: YouTube Demo Video

Generative Adversarial Networks (GANs) & Federated Learning
For my master's thesis, I implemented a Generative Adversarial Network (GAN) using non-i.i.d. time-series data in a Federated Learning setting at Scania CV AB, a leading provider of commercial vehicles. The aim was to generate synthetic data for a specific vehicle system to avoid the costly and risky process of manually collecting anomalous data.
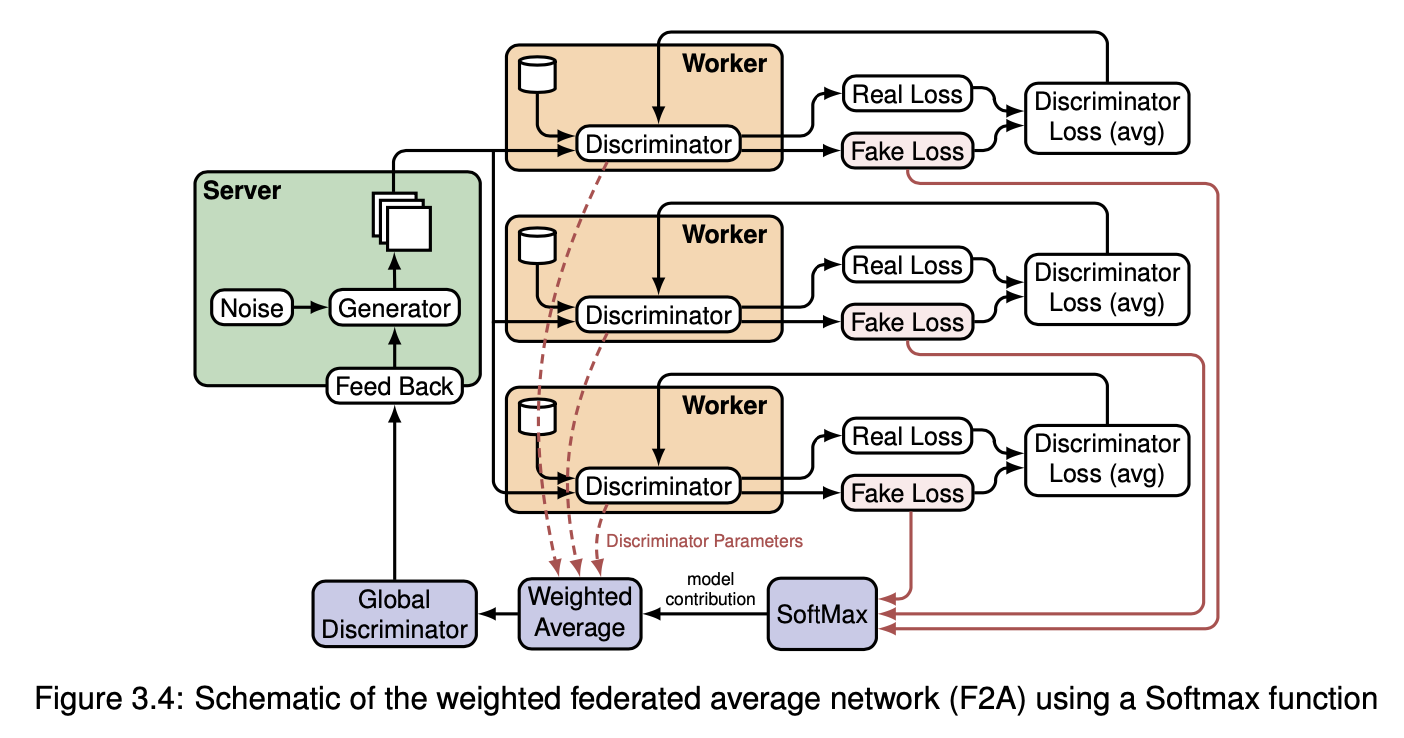
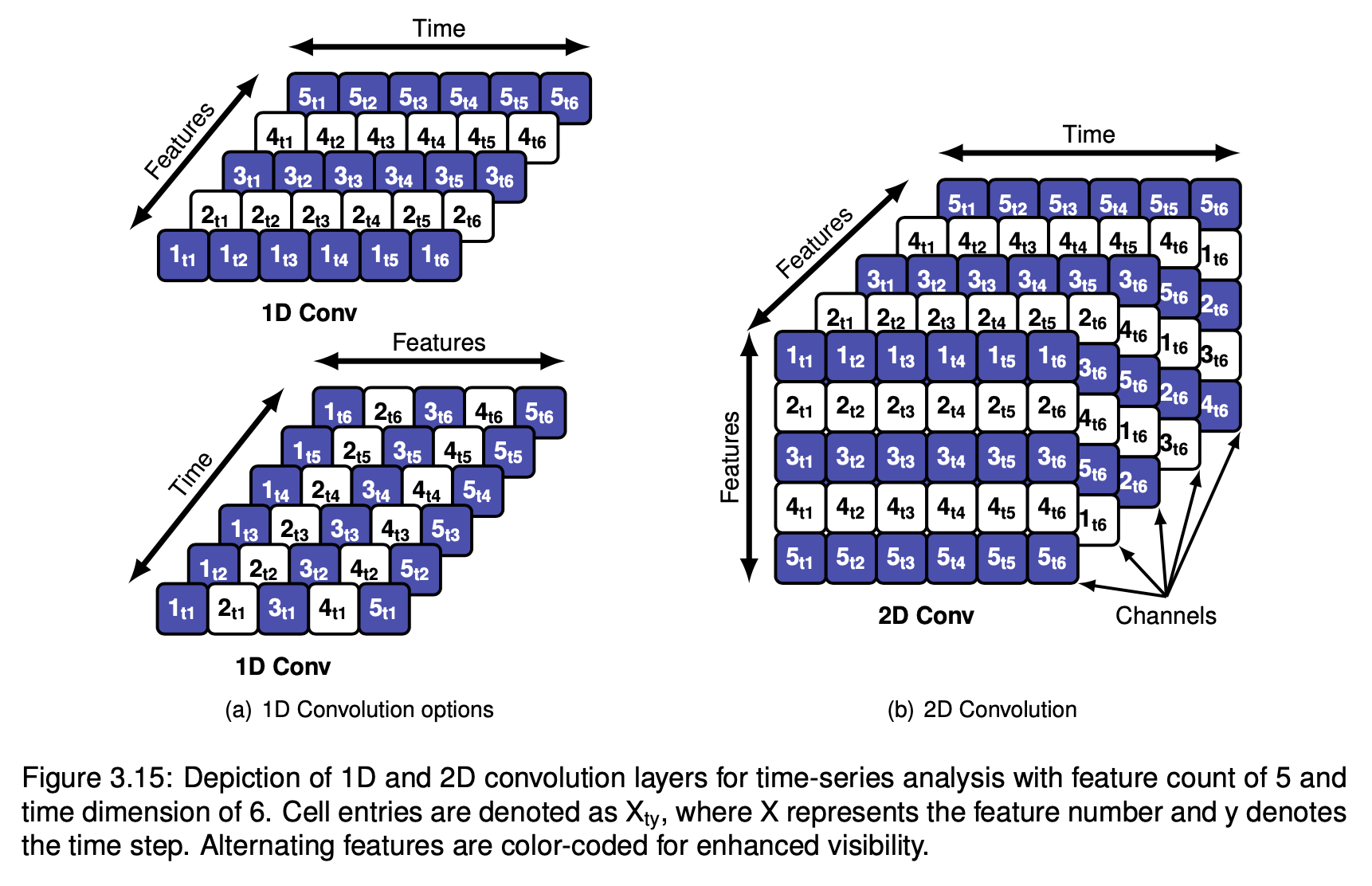
I evaluated various image-based strategies and identified the most effective one for decentralized learning. The GAN was based on a deep Convolutional Neural Network (CNN) architecture, and after testing various mutations, the final architecture used 1D convolution layers along with Spectral Normalization to stabilize the discriminator training.
I employed the use of adaptive average pooling after the convolution layers to make the network work with inputs of different sizes to use a dynamic window instead of a static one. This improves the capabilities of the generator to create sequences of different sizes.
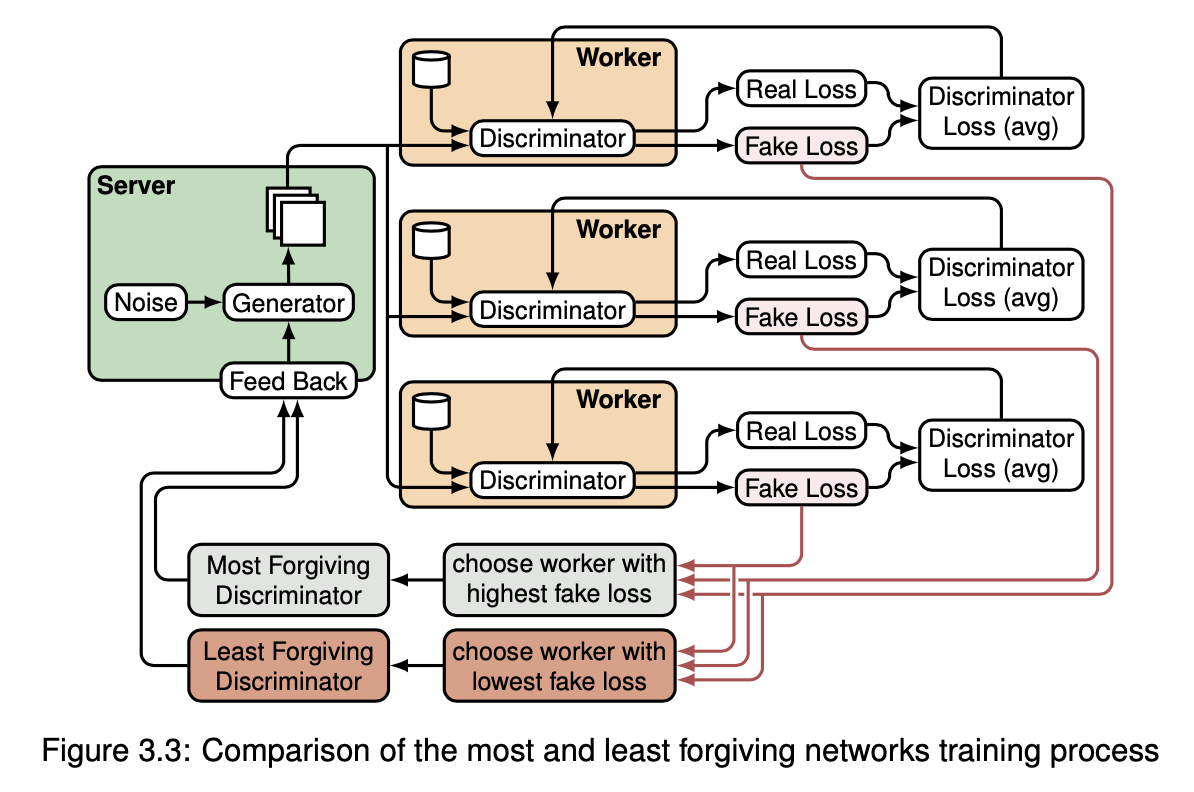
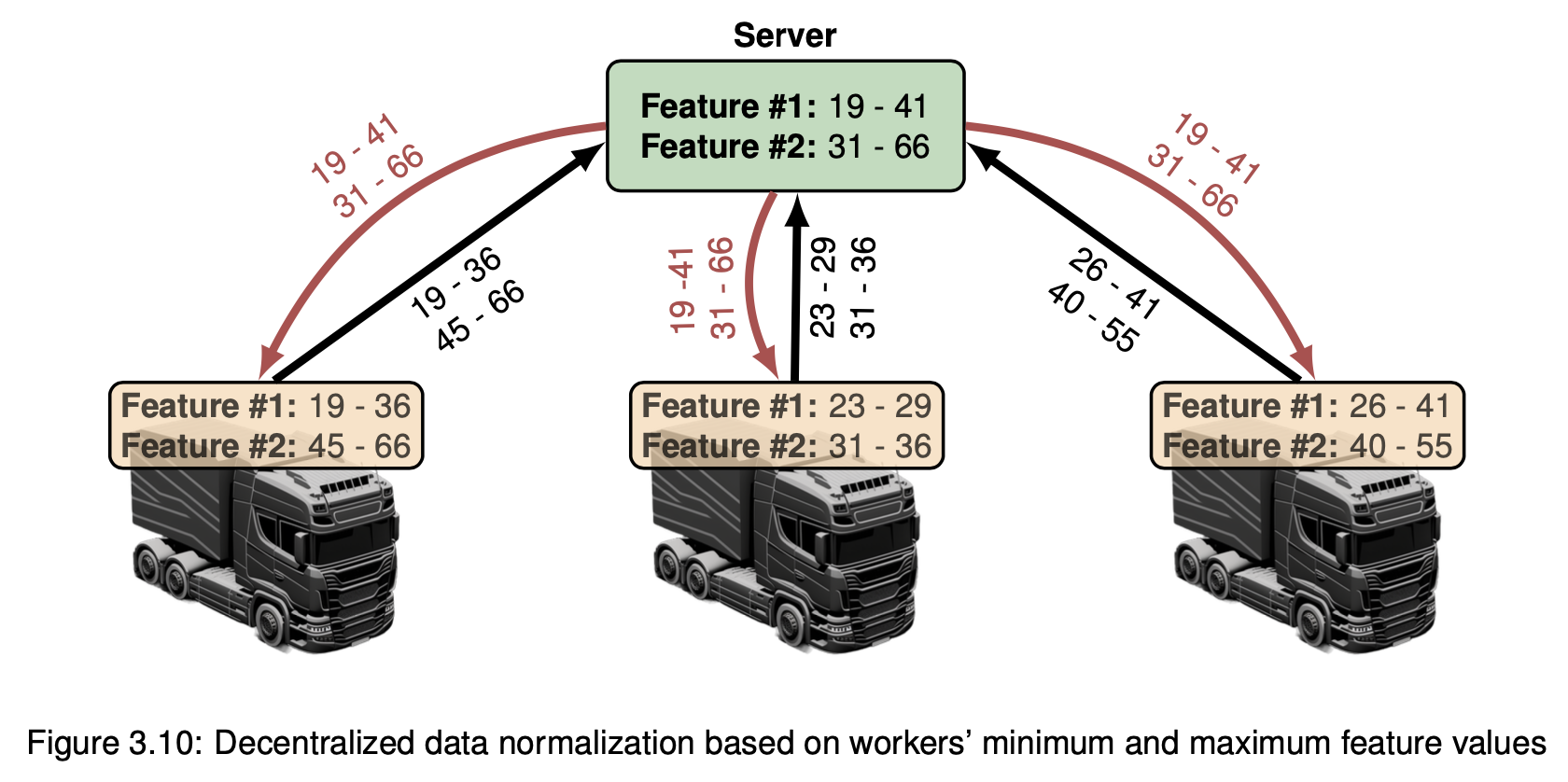
I proposed a novel normalization technique to further enhance the training process. More in details, the server determines the global minimum and maximum values for each feature, considering the lowest minimum and the highest maximum values received from all the workers. These global boundaries are then sent back to all workers for normalization of their local data.
The model was proven to effectively learn from multiple non-IID time-series and converge to a solution that fools all discriminators. Experimental results show that the approach outperforms existing centralized methods, such as TimeGAN, for non-IID time-series in terms of the quality of the generated synthetic data.
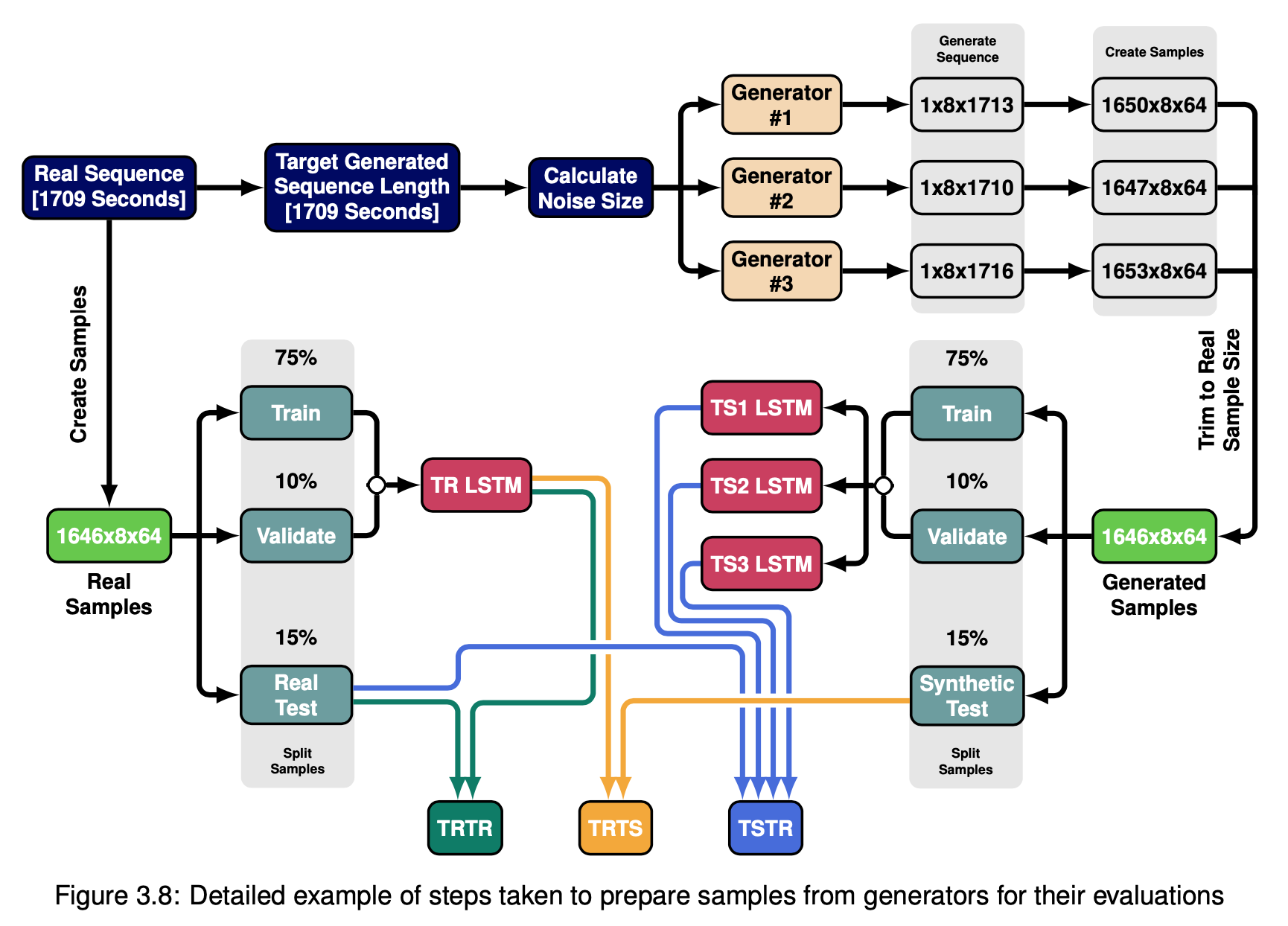
To evaluate time-series based output, I developed an LSTM-based auto-regression model using two training methods and three evaluation metrics. the two methods were Train on Synthetic Test on Real (TSTR) and Train on Real Test on Synthetic (TRTS) and three metrics were calculated: R2 score, MAE, and RMSE.
You can find the report of the thesis [here]. The thesis was succesfully published in IEEE: [publication link].
Deep Q Learn - Pendulum
In this project, I trained a Deep Q network to control a pendulum's torque, enabling it to perform a "handstand maneuver". I leveraged TensorFlow and Keras to create two neural networks:
- A primary Q-value function aimed at minimization using Stochastic Gradient Descent (SGD).
- A target Q-value function used as a goal for the primary Q-value function. To stabilize the algorithm, I maintained its weights constant for an extended number of iterations, preventing a constantly moving target.
Through experimentation and optimization, I fine-tuned the hyperparameters essential for the algorithm's performance. I used an (ε) greedy policy with an exponential decay, promoting broad exploration initially, followed by exploitation in later episodes to reduce cost.
To create more independent data points for training the Q-value function, I used a replay buffer holding a set number of observations, replacing older ones with new data when full. I also implemented periodic model storage to safeguard against potential algorithm divergence.
For a deeper dive into the project, check out the GitHub repository: [Link].

Who is the Payer: Using ML Analysis
Addressing work orders and determining the payer at Scania was a time-consuming task, prompting the initiation of a project to explore how machine learning (ML) could expedite this process. I collaborated with the relevant team members to gather necessary data (features) for decision-making, and the project encompassed the following stages:
- Data collection: I worked closely with team members to gather critical data and features for decision-making.
- Pre-processing: Using techniques like scaling, encoding, and feature selection, I prepared the collected data for ML algorithms.
- Model selection and training: I tested multiple ML algorithms, including linear regression, random forest, support vector machines, and MLPs, to identify the best-performing model for our dataset.
- Model evaluation and prediction: Each model's performance was assessed using cross-validation and various evaluation metrics such as accuracy, precision, and recall. I then used the best-performing model to make predictions on new data to identify the payer.
This project not only streamlined the decision-making process but also showcased my proficiency in data analysis, pre-processing, and applying ML techniques for predictive purposes.
Deceptive Reviews Detection Using One-Class SVM Research
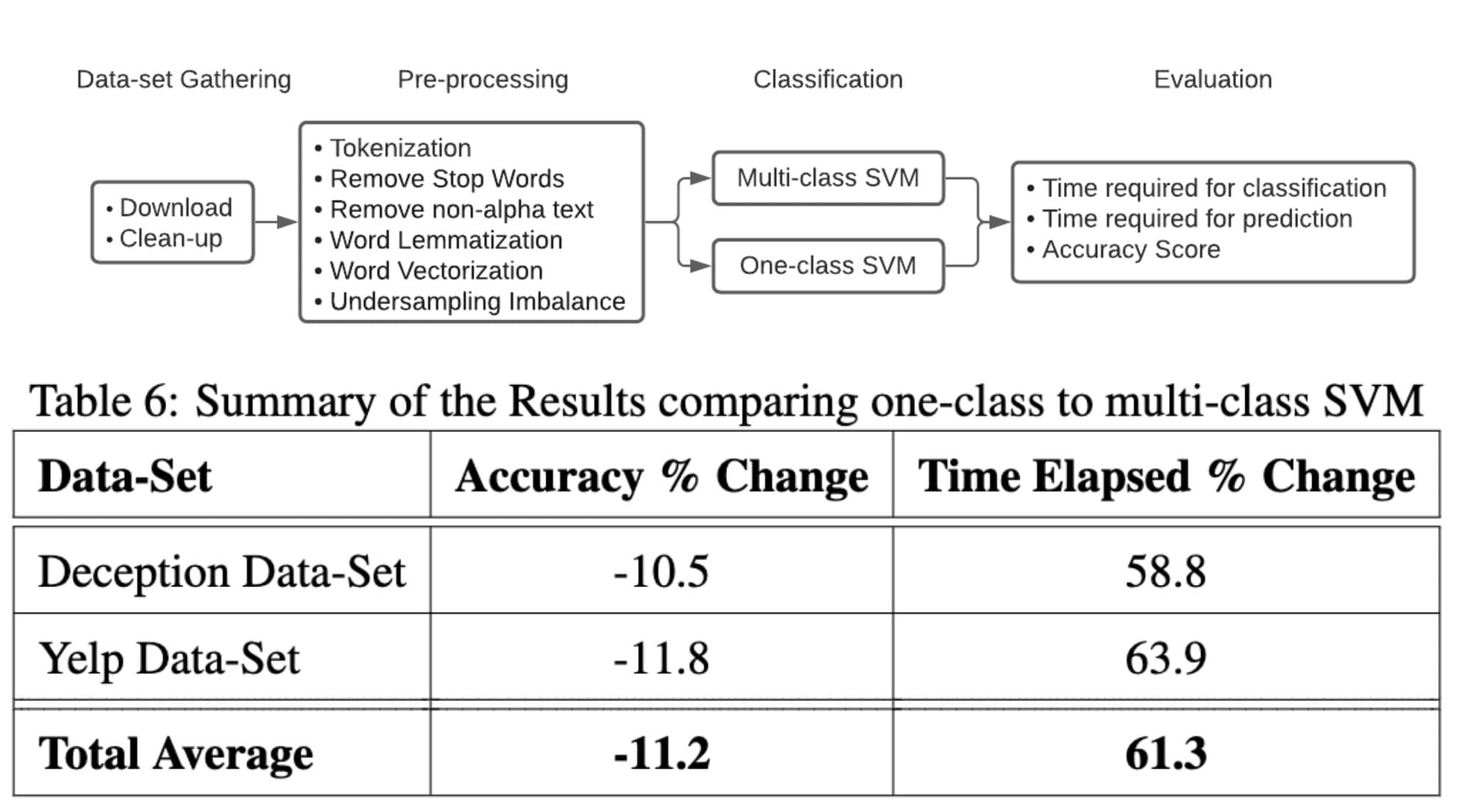
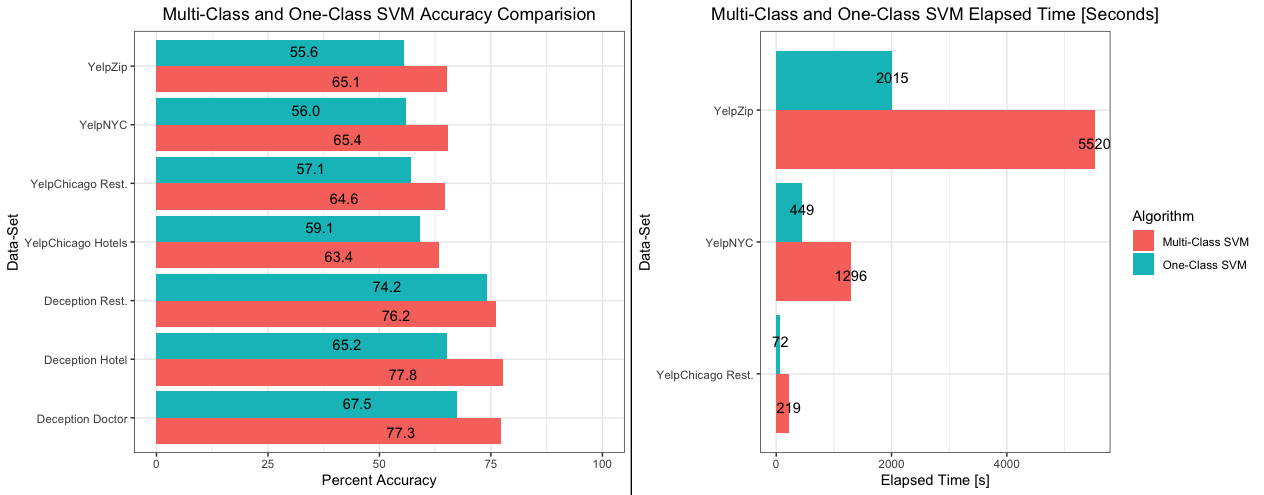
This project explored the effectiveness of a One-Class Support Vector Machine (SVM) in identifying deceptive online reviews. I theorized that training on genuine reviews alone could spot deceptive ones, reducing training and inference time and data requirements.
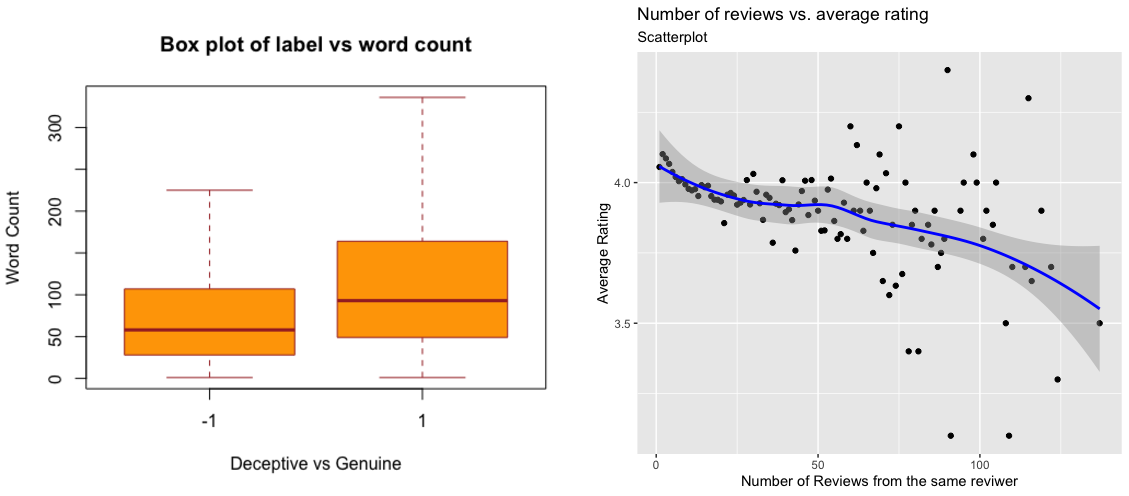
A One-Class SVM, an unsupervised learning approach, is often used for anomaly detection in datasets. It trains on normal data, defines boundaries, and classifies points outside those boundaries. Multiple datasets were collected, cleaned, and merged using R studio and Pandas, followed by some preliminary statistical analyses.
I performed extensive pre-processing through Natural Language Processing (NLP) to transform text into a form suitable for the neural network. This process involved tokenization, stop word and non-alpha text removal, word lemmatization, word vectorization, and undersampling to balance the datasets.
However, the research results indicated that One-Class SVM, despite its time efficiency, was less effective than multi-class SVM due to the diverse review content. The study concluded that linguistic features alone are insufficient to detect real-life fake reviews but suggested that a user-level deployment of One-Class SVM could potentially identify unusual user posting behaviors.
Handwriting Data Detection
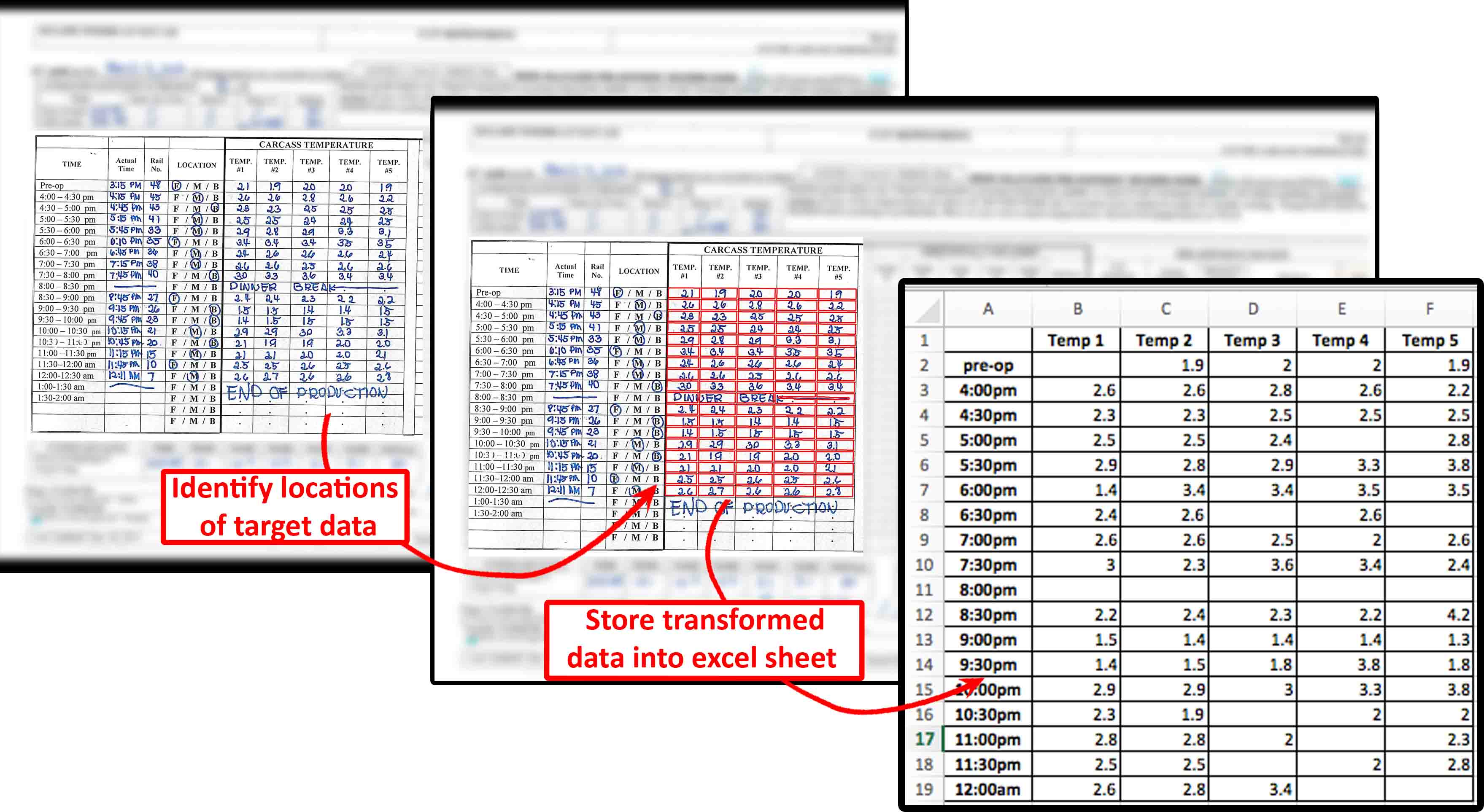
This project required processing a vast number of scanned documents with tabular data containing handwritten numerical entries, aiming to digitize the handwritten data accurately for easy analysis and management.
I trained a Convolutional Neural Network (CNN) with TensorFlow to recognize handwritten digits, using the extensive MNIST dataset for training. To enhance the CNN model's accuracy, I used OpenCV for document pre-processing, which included:
- Gaussian Blur: To reduce image noise and minimize handwriting variations.
- Thresholding: To convert images into a binary format, simplifying handwritten data detection.
- Dilatation and Erosion: To refine the binary images, eliminating minor artifacts and enhancing handwritten data visibility.
- Find Contours: To detect table edges within scanned documents.
- Bounding Rectangles, Convex Hull: To identify individual table cells.
After extraction, I processed and structured the handwritten data with the Pandas library and saved the cleaned data into digital Excel sheets for subsequent analysis and manipulation.
Simple Neural Network Digit Classifier
In this project, I created a simple neural network without using any frameworks to delve deeper into their structure. The network was specifically tailored for the MNIST dataset and consisted of three layers:
- Zeroth layer: Comprising of 784 inputs as it accepts a 28x28 pixel image.
- First layer: A hidden layer with 10 nodes.
- Second layer: An output layer with 10 nodes, each representing a digit from 0-9.
Training the network involved the following steps:
- Initialize random weights and biases.
- Perform forward propagation using the weights and biases (Z = W.A + b), where:
- The first layer is calculated and a rectified linear unit (Relu) activation is applied to make it non-linear.
- The second layer is calculated and a softmax activation function is applied to obtain probabilities.
- Backward propagation is then applied:
- Calculate the error between prediction and actual value (dZ = A - Y).
- Determine the contribution of each weight and bias to the error.
- Update the weights and biases based on your learning rate alpha (hyper parameter).
Check out the full project on GitHub: Link.
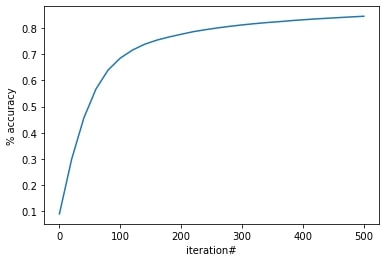
KTH Machine Learning Projects
In this series of projects, I gained foundational knowledge of significant algorithms and theory in machine learning. This was achieved through lab work, where I implemented various machine learning algorithms, including:
- Face classification using Boosted Decision Trees.
- Support Vector Machines.
- Bayes Classifier with Adaboost algorithm.
I built and trained different classifiers on a labeled dataset, which were later used to infer labels on an unlabeled evaluation dataset. The following machine learning algorithms were used with their respective accuracy results:
- Logistic Regression: 0.809 (0.029)
- Linear Discriminant Analysis: 0.811 (0.034)
- K Nearest Neighbor: 0.816 (0.041)
- Decision Tree Classifier: 0.784 (0.035)
- Gaussian Naive Bayes: 0.842 (0.043)
- Support Vector Machine: 0.850 (0.030)
- Random Forest: 0.859 (0.020)
The best-performing model, given the nature of the dataset, was the Random Forest.
For more information, visit the GitHub repository: [Link].